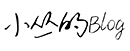

搭建集群时需要在多台机器之间同步文件,故本文使用了集群间文件分发脚本
xsync,该脚本原理可以参考集群间文件分发脚本
创建分发脚本
先在host5机器上创建xsync脚本
切换到root用户
su - root
创建脚本
vim /usr/local/bin/xsync
脚本内容
注意:脚本中的 host5 host6 host7 需要小配置hosts映射 如不映射需要填写具体机器的ip
#!/bin/bash
#1. 参数校验,参数小于1 即不传递参数时,提示
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群中的所有机器,这里做了hostname和ip的映射直接使用 hostname遍历集群,hostname和ip映射见http://cong.zone/archives/centos7%E4%BF%AE%E6%94%B9%E4%B8%BB%E6%9C%BA%E5%90%8D%E7%A7%B0
for host in host5 host6 host7
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
给脚本授可执行权限
chmod +x /usr/local/bin/xsync
安装jdk
使用java -version确定是否由java环境

上图是没有java环境需要安装配置java
mkdir /root/app
下载亚马逊jdk
wget https://corretto.aws/downloads/latest/amazon-corretto-8-x64-linux-jdk.tar.gz
解压安装包
tar -zxvf amazon-corretto-8-x64-linux-jdk.tar.gz
重命名
mv amazon-corretto-8.332.08.1-linux-x64/ jdk8-corretto

配置环境变量
vim /etc/profile
#java environment
export JAVA_HOME=/root/app/jdk8-corretto
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin

加载配置
source /etc/profile
验证安装
java -version

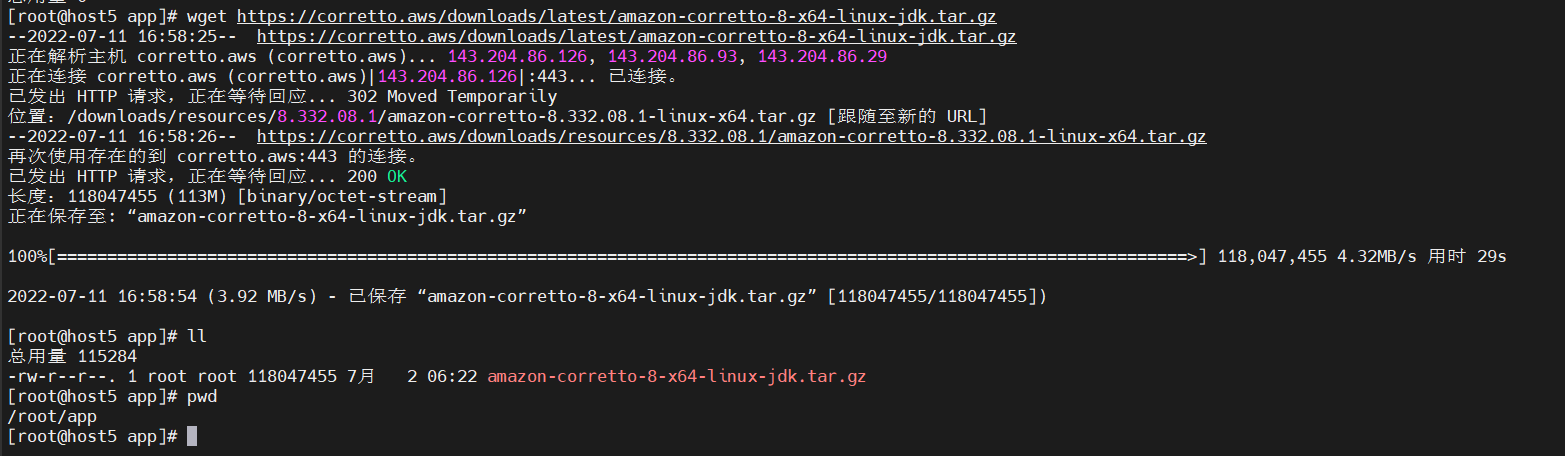
使用xsync将jdk分发到 host6 和 host7
根据交互提示和输入 yes 和 密码
在host6 host7 查看

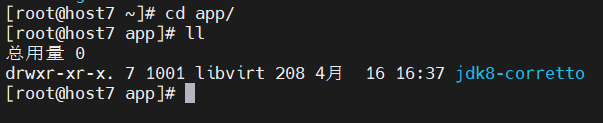
可以看到jdk已经传到了这两台机器
继续同步配置环境变量文件
xsync /etc/profile
同步后重新加载配置并验证
source /etc/profile
java -version


三台机器都成功的配置了java环境
安装部署
集群规划
| 主机名 | host5 | host6 | host7 |
|---|---|---|---|
| 应用1 | zookeeper | zookeeper | zookeeper |
| 应用2 | kafka | kafka | kafka |
集群部署
本文选择3.0.1版本
下载kafka安装包
我这里放在了/root/app目录 其他目录也可以
cd /root/app
wget https://archive.apache.org/dist/kafka/3.0.1/kafka_2.12-3.0.1.tgz
解压kafka安装包
tar -zxvf kafka_2.12-3.0.1.tgz
修改目录名称
mv kafka_2.12-3.0.1/ kafka
修改配置文件
进入到/root/app/kafka 目录,
cd /root/app/kafka/config
vim server.properties
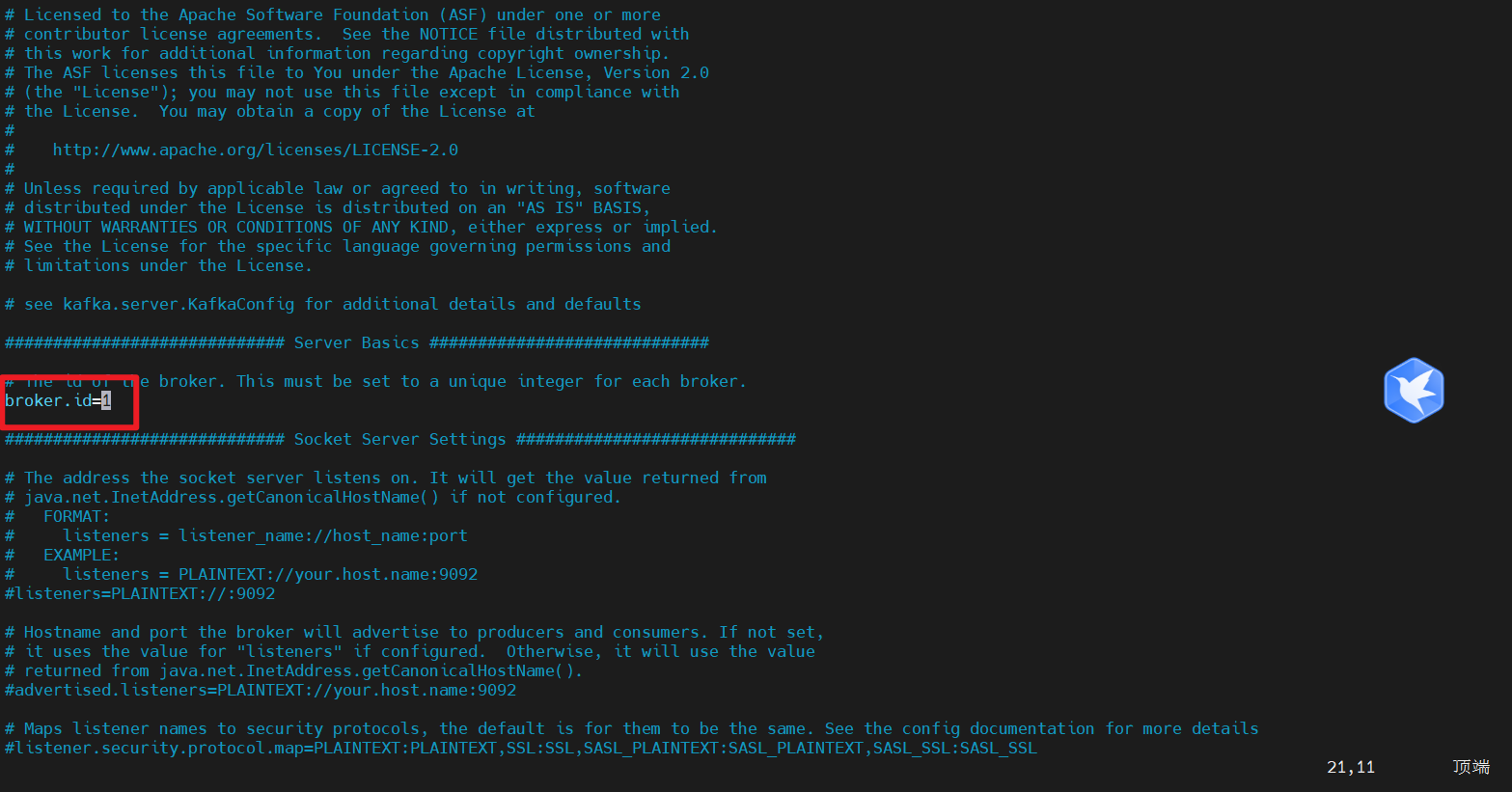
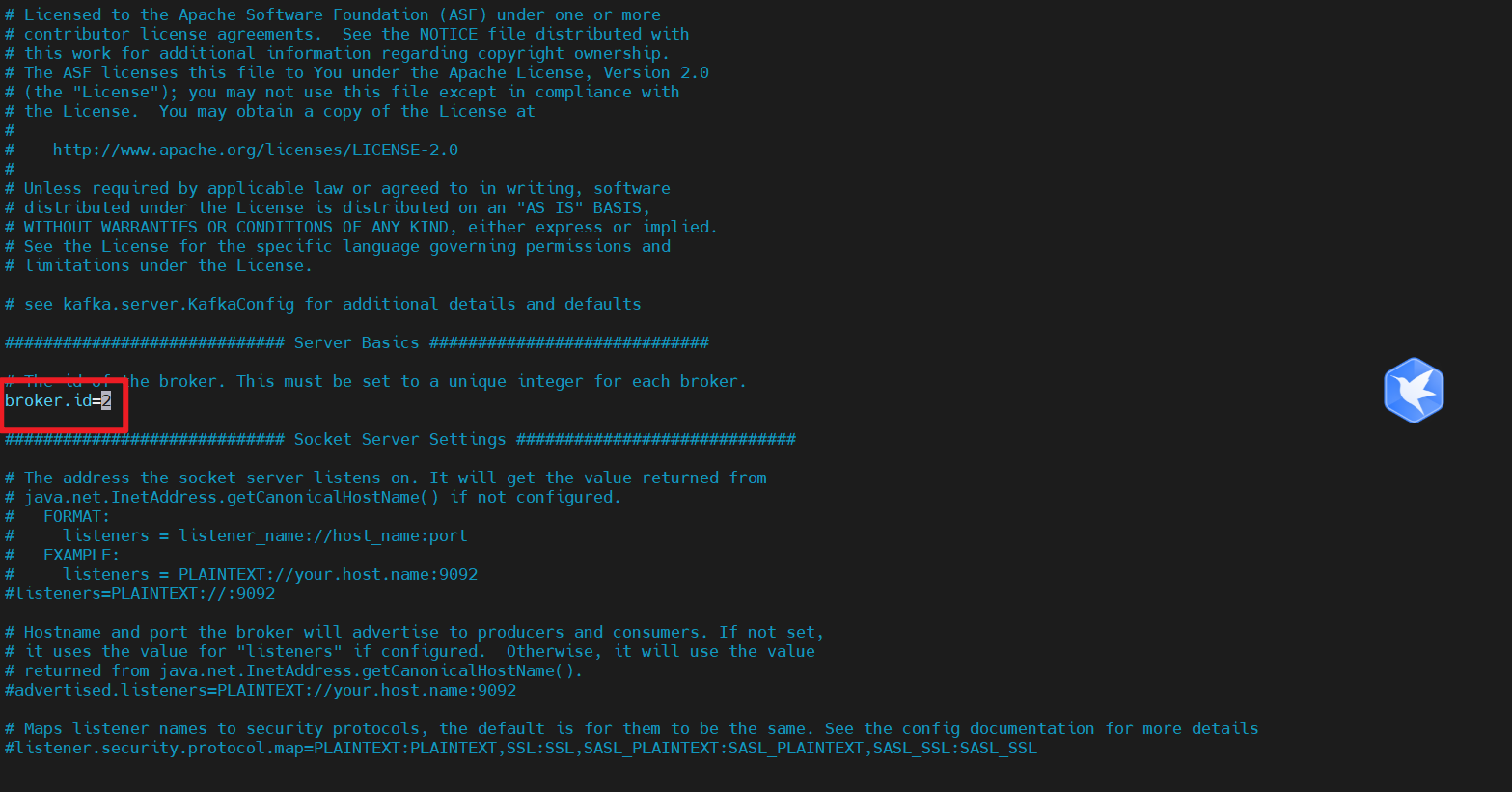
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/root/app/kafka/datas
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=host5:2181,host6:2181,host7:2181/kafka
分发安装包
xsync /root/app/kafka/
分发完成后
分别在 host6 和 host7上修改配置文件/root/app/kafka/config/server.properties中的 broker.id=1、broker.id=2
注:broker.id 不得重复,整个集群中唯一。
vim /root/app/kafka/config/server.properties
配置环境变量
sudo vim /etc/profile
在文件末尾追加如下配置
#KAFKA_HOME
export KAFKA_HOME=/root/app/kafka
export PATH=$PATH:$KAFKA_HOME/bin
重新加载配置文件
source /etc/profile
分发配置文件并在host6 和 host7 上重新加载
xsync /etc/profile
分别重新加载
source /etc/profile
安装zookeeper
下载安装包
cd /root/app
wget https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
解压缩
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz
重命名目录
mv apache-zookeeper-3.6.3-bin zookeeper
将解压后的zookeeper分发到其他两台机器
xsync /root/app/zookeeper/
配置服务器编号
在/root/app/zookeeper/这个目录下创建zkData
mkdir zkData
在/root/app/zookeeper/zkData目录下创建一个zkid的文件
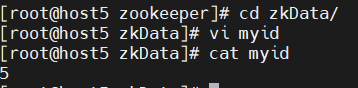
cd zkData
vi myid
文件内容为编号5,host6 和 host7的 文件内容分别为 6 和 7
5
分发编号文件
xsync /root/app/zookeeper/zkData/myid
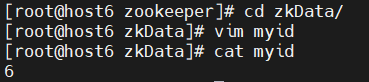
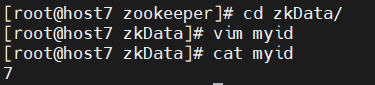
分发后修改zkid文件内容为指定标号,结果如下图所示
配置zoo.cfg文件
重命名/root/app/zookeeper/conf这个目录下的zoo_sample.cfg为zoo.cfg
cd /root/app/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
编辑zoo.cfg
vim zoo.cfg
修改数据存储路径配置
dataDir=/root/app/zookeeper/zkData
增加如下配置
server.5=host5:2888:3888
server.6=host6:2888:3888
server.7=host7:2888:3888
最终文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/root/app/zookeeper/zkData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.5=host5:2888:3888
server.6=host6:2888:3888
server.7=host7:2888:3888
分发zoo.cfg配置文件到host6 和 host7
xsync /root/app/zookeeper/conf/zoo.cfg
配置参数说明
server.A=B:C:D
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
启动zookeeper集群
三台机器分别启动Zookeeper
host5
cd /root/app/zookeeper/bin/
./zkServer.sh start
host6
cd /root/app/zookeeper/bin/
./zkServer.sh start
host7
cd /root/app/zookeeper/bin/
./zkServer.sh start
查看状态
host5
./zkServer.sh status
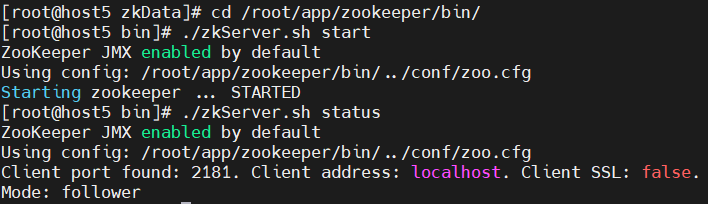
host6
./zkServer.sh status
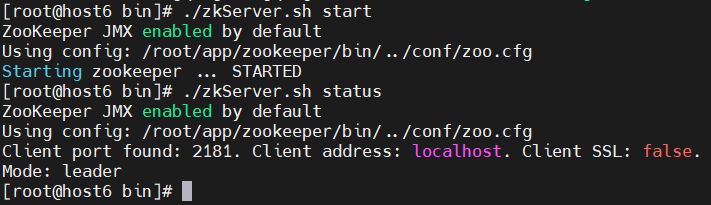
host7
./zkServer.sh status
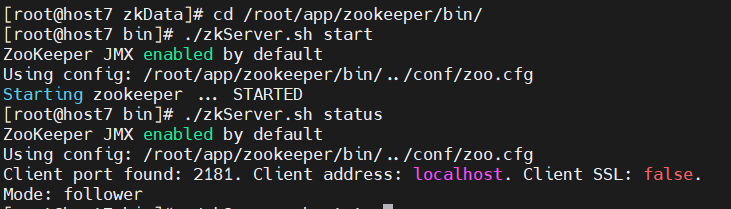
zookeeper客户端命令行操作
| 命令 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
启动客户端
/root/app/zookeeper/bin/zkCli.sh
ZK集群启动停止脚本
在host5/usr/local/bin目录下创建脚本
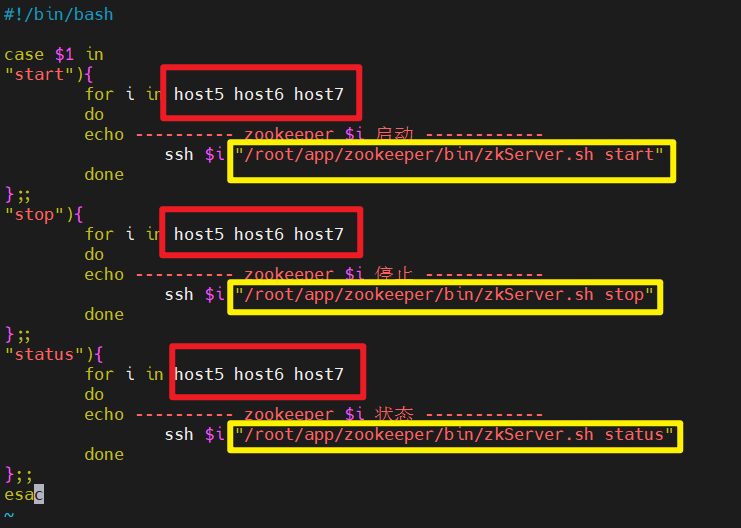
vim /usr/local/bin/zk.sh
在脚本中编写如下内容
注意修改 机器名和zookeeper的bin目录
#!/bin/bash
case $1 in
"start"){
for i in host5 host6 host7
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/root/app/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in host5 host6 host7
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/root/app/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in host5 host6 host7
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/root/app/zookeeper/bin/zkServer.sh status"
done
};;
esac
给脚本授执行权限
chmod +x /usr/local/bin/zk.sh
启动kafka
先启动 Zookeeper 集群,然后启动 Kafka。依次在 host5、host6、host7 节点上启动 Kafka。
host5
cd /root/app/kafka/
./bin/kafka-server-start.sh -daemon config/server.properties
host6
cd /root/app/kafka/
./bin/kafka-server-start.sh -daemon config/server.properties
host6
cd /root/app/kafka/
./bin/kafka-server-start.sh -daemon config/server.properties
注意:配置文件的路径要能从当前路径推断出 server.properties,或者可以使用绝对路径
kafka集群启停脚本
待完成

评论区